from what I know, da denoise dat Appian and Marston use are really light… the magic really comes from sourcing best available material and using the right kind of needle and downweight for the initial transfer.
2 Likes
yeah both these performances are nasty, when I put on the record for the first time at my friend’s house (I don’t have a 78 player) I was almost sweating… The whole personal story behind Klein and getting miraculously lucky and finding the record and ordering it from a wartorn Ukraine was enough…
Then I started to think wait, what if it’s not that good? What if after all this, he was just a mediocre pianist? And then the campy started to play and my jaw was on the floor hahah
4 Likes
Sounds like it’s being played with a wrong (smaller) styuls. The noise is overbearing, which isn’t very characteristic of these syrenas, even taking the condition into account. Sick rec nonetheless!
1 Like
Yeah it seemed difficult to take much noise out without having a bit of a munch at the overall texture.
screenshots to give an idea of the noise to signal levels:
before:
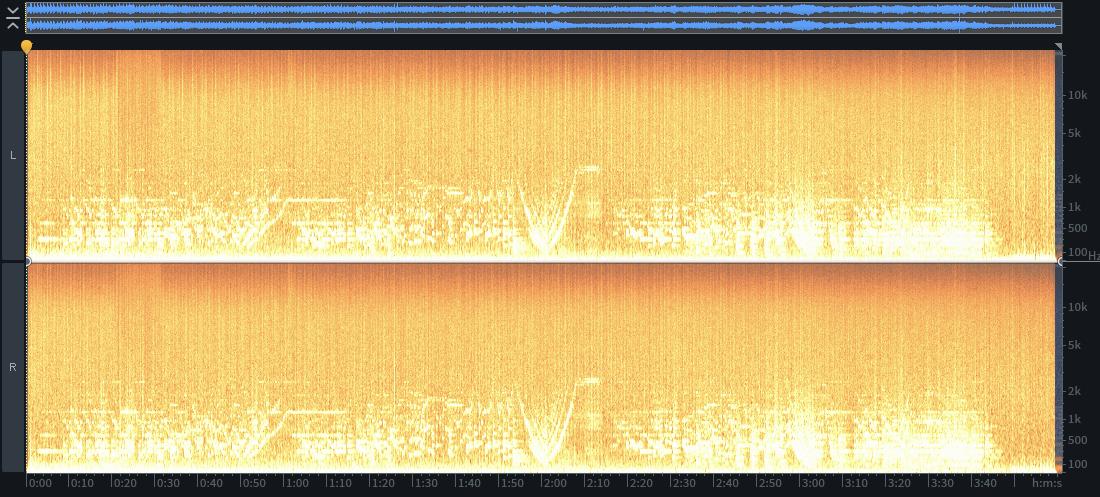
after:
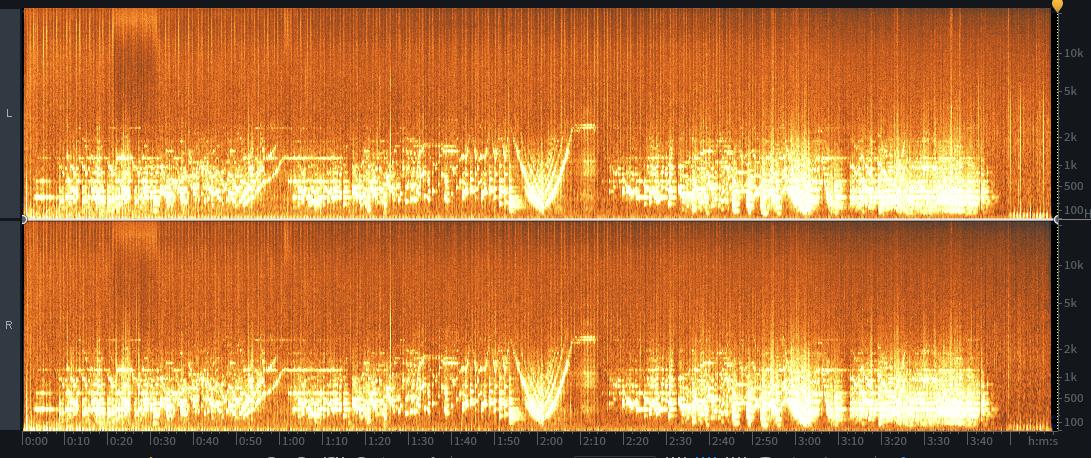
Still haven’t figured out how to repair code in that historical AI noise reduction. Will drink some redbulls and see what I can do. Will be lame if I gotta download and convert weights.
add
!pip install tensorflow==2.15.0
at da start
1 Like
Yeah exactly.
That’s why da hisstorical labels focus on getting the best analog transfer and then declick. Some curves in there, sure, but not aimed at noise reduction
woh, I forget the Knar knows the spells hat have dominion over this space. Will tinker. I got sidetracked making fish tacos at 9AM
#unemploymentisgreat
2 Likes
I think the knar code tweak is working. Will paste raw text code here when confirm file gets denoised here in a few.
1 Like
Whoa this a pubic thread.
So no disclosures about how Klauz Schwab impregnated me on a spaceship?
1 Like
The resulting baby:
2 Likes
Only a day for a full derail
1 Like

Ok here the AI denoised files. Probably need some chirpy cleanup and to mix back in with raw file a bit so not too nubby but def easier to make out stuff.
Here the code that works now. Might be HTMLified. Meh… if someone needs it ping me for .txt file to paste
Install TensorFlow and other dependencies
!pip install tensorflow==2.15.0
!pip install hydra-core==0.11.3
Download the files
!git clone GitHub - eloimoliner/denoising-historical-recordings: A two-stage U-Net for high-fidelity denoising of historical recordings
!wget https://github.com/eloimoliner/denoising-historical-recordings/releases/download/v0.0/checkpoint.zip
!unzip checkpoint.zip -d denoising-historical-recordings/experiments/trained_model/
%cd denoising-historical-recordings
All the code goes here
import unet
import tensorflow as tf
import soundfile as sf
import numpy as np
from tqdm import tqdm
import scipy.signal
import hydra
import os
Workaround to load hydra conf file
import yaml
from pathlib import Path
args = yaml.safe_load(Path(‘conf/conf.yaml’).read_text())
class dotdict(dict):
“”“dot.notation access to dictionary attributes”“”
getattr = dict.get
setattr = dict.setitem
delattr = dict.delitem
args = dotdict(args)
unet_args = dotdict(args.unet)
path_experiment = str(args.path_experiment)
unet_model = unet.build_model_denoise(unet_args=unet_args)
ckpt = os.path.join(“/content/denoising-historical-recordings”, path_experiment, ‘checkpoint’)
unet_model.load_weights(ckpt)
def do_stft(noisy):
window_fn = tf.signal.hamming_window
win_size = args.stft[“win_size”]
hop_size = args.stft[“hop_size”]
stft_signal_noisy = tf.signal.stft(noisy, frame_length=win_size, window_fn=window_fn, frame_step=hop_size, pad_end=True)
stft_noisy_stacked = tf.stack(values=[tf.math.real(stft_signal_noisy), tf.math.imag(stft_signal_noisy)], axis=-1)
return stft_noisy_stacked
def do_istft(data):
window_fn = tf.signal.hamming_window
win_size = args.stft[“win_size”]
hop_size = args.stft[“hop_size”]
inv_window_fn = tf.signal.inverse_stft_window_fn(hop_size, forward_window_fn=window_fn)
pred_cpx = data[...,0] + 1j * data[...,1]
pred_time = tf.signal.inverse_stft(pred_cpx, win_size, hop_size, window_fn=inv_window_fn)
return pred_time
def denoise_audio(audio):
data, samplerate = sf.read(audio)
if len(data.shape) > 1: # Stereo
channel_1 = data[:, 0]
channel_2 = data[:, 1]
else: # Mono
channel_1 = data
channel_2 = np.zeros_like(data)
if samplerate != 44100:
channel_1 = scipy.signal.resample(channel_1, int((44100 / samplerate) * len(channel_1)) + 1)
channel_2 = scipy.signal.resample(channel_2, int((44100 / samplerate) * len(channel_2)) + 1)
def process_channel(data):
segment_size = 44100 * 5 # 20s segments
length_data = len(data)
overlapsize = 2048 # samples (46 ms)
window = np.hanning(2 * overlapsize)
window_right = window[overlapsize::]
window_left = window[0:overlapsize]
audio_finished = False
pointer = 0
denoised_data = np.zeros(shape=(len(data),))
residual_noise = np.zeros(shape=(len(data),))
numchunks = int(np.ceil(length_data / segment_size))
for i in tqdm(range(numchunks)):
if pointer + segment_size < length_data:
segment = data[pointer:pointer + segment_size]
segment_TF = do_stft(segment)
segment_TF_ds = tf.data.Dataset.from_tensors(segment_TF)
pred = unet_model.predict(segment_TF_ds.batch(1))
pred = pred[0]
residual = segment_TF - pred[0]
residual = np.array(residual)
pred_time = do_istft(pred[0])
residual_time = do_istft(residual)
residual_time = np.array(residual_time)
if pointer == 0:
pred_time = np.concatenate((pred_time[0:int(segment_size - overlapsize)], np.multiply(pred_time[int(segment_size - overlapsize):segment_size], window_right)), axis=0)
residual_time = np.concatenate((residual_time[0:int(segment_size - overlapsize)], np.multiply(residual_time[int(segment_size - overlapsize):segment_size], window_right)), axis=0)
else:
pred_time = np.concatenate((np.multiply(pred_time[0:int(overlapsize)], window_left), pred_time[int(overlapsize):int(segment_size - overlapsize)], np.multiply(pred_time[int(segment_size - overlapsize):int(segment_size)], window_right)), axis=0)
residual_time = np.concatenate((np.multiply(residual_time[0:int(overlapsize)], window_left), residual_time[int(overlapsize):int(segment_size - overlapsize)], np.multiply(residual_time[int(segment_size - overlapsize):int(segment_size)], window_right)), axis=0)
denoised_data[pointer:pointer + segment_size] = denoised_data[pointer:pointer + segment_size] + pred_time
residual_noise[pointer:pointer + segment_size] = residual_noise[pointer:pointer + segment_size] + residual_time
pointer = pointer + segment_size - overlapsize
else:
segment = data[pointer::]
lensegment = len(segment)
segment = np.concatenate((segment, np.zeros(shape=(int(segment_size - len(segment)),))), axis=0)
audio_finished = True
segment_TF = do_stft(segment)
segment_TF_ds = tf.data.Dataset.from_tensors(segment_TF)
pred = unet_model.predict(segment_TF_ds.batch(1))
pred = pred[0]
residual = segment_TF - pred[0]
residual = np.array(residual)
pred_time = do_istft(pred[0])
pred_time = np.array(pred_time)
pred_time = pred_time[0:segment_size]
residual_time = do_istft(residual)
residual_time = np.array(residual_time)
residual_time = residual_time[0:segment_size]
if pointer == 0:
pred_time = pred_time
residual_time = residual_time
else:
pred_time = np.concatenate((np.multiply(pred_time[0:int(overlapsize)], window_left), pred_time[int(overlapsize):int(segment_size)]), axis=0)
residual_time = np.concatenate((np.multiply(residual_time[0:int(overlapsize)], window_left), residual_time[int(overlapsize):int(segment_size)]), axis=0)
denoised_data[pointer::] = denoised_data[pointer::] + pred_time[0:lensegment]
residual_noise[pointer::] = residual_noise[pointer::] + residual_time[0:lensegment]
return denoised_data
denoised_channel_1 = process_channel(channel_1)
denoised_channel_2 = process_channel(channel_2)
denoised_stereo = np.column_stack((denoised_channel_1, denoised_channel_2))
return denoised_stereo
Upload file to denoise
Execute this cell to upload a single audio recording you would like to denoise (accepted extensions: .wav, .flac, .mp3)
from google.colab import files
uploaded = files.upload()
Denoise
Execute this cell to denoise the uploaded file
for fn in uploaded.keys():
print(f’Denoising uploaded file “{fn}”')
denoised_data = denoise_audio(fn)
basename = os.path.splitext(fn)[0]
wav_output_name = basename + “_denoised” + “.wav”
sf.write(wav_output_name, denoised_data, 44100, subtype=‘PCM_24’)
Download
Execute this cell to download the denoised recording
files.download(wav_output_name)
can click “share” in the notebook
(h̶̢͔̤̲̹̲͇̆̏̽̇̋̔͌a̸̤̦͒̽ͅc̶̠̝̒̿̄̆̽̈́̓k̵͈͊è̷̘̝̼̘͇͚̮̓͝ṛ̵̢̌̈́̃̊̏ technique)
2 Likes

2 Likes
Reminds me of Kamala talking about “the cloud” and about AI.
1 Like
I like how it hesitatez between a oboe and a piano in da first 2 zecz
1 Like